These permissions can be assigned to any user group as you see fit. If required, multiple permissions can be assigned to the same group too. For an example take an LDAP server which defines 3 different user groups – A,B and C. By properly assigning the above permissions to the respective groups, we can designate users in group-A as API creators, users in group-B as API publishers and users in group-C as subscribers. If we grant both Create and Publish permissions to group-A, users in that group will be able to both create and publish APIs.
Lets take an API Manager 1.0.0-Beta1 pack and try some of these stuff out.
Download the binary distribution and extract it to install the product. Go to the "bin" directory of the installation and launch the wso2server.sh file (or wso2server.bat if you are on Windows) to start the server. Once the server has fully started up, start your web browser and go to the URL https://localhost:9443/carbon. You should get to the login page of WSO2 API Manager management console.
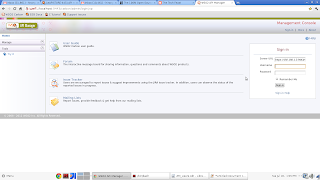
Login to the console using default admin credentials (user: admin, pass: admin). Select the 'Configure' tab and click on 'Users and Roles' from the menu to open the "User Management" page.
Lets start by adding a couple of new roles. Click on “Roles” which will list all the currently existing roles. WSO2 API Manager uses an embedded H2 database engine as the default user store. So if you were wondering where the user 'admin' and the default roles are stored, there's your answer. To use a different user store such as an external LDAP server, you need to configure the repository/conf/user-mgt.xml file accordingly.
You will notice 3 roles in the listing – admin, everyone and subscriber. The default "subscriber" role has the "Manage > API > Subscribe" permission. But don't get the wrong idea that the system is somehow tied into this role. The default "subscriber" role is created by the self sign up component of API Manager and it is fully configurable. I will get back to that later. For now click on the “Add New Role” option and start the role creation wizard.
Enter the name “creator” as the role name and click “Next”.
From the permission tree select the “Configure > Login” and “Manage > API > Create” permissions and click “Next”.
You will be asked to add some users to the newly created role. But for now simply click on “Finish” to save the changes and exit the wizard. You will now see the new “creator” permission also listed on the “Roles” page. Start the role creation wizard once more to add another role named “publisher”. Assign the “Configure > Login” and “Manage > API > Publish” permission to this role.
Now lets go ahead and create a couple of user accounts and add them to the newly created roles. Select “Users and Roles” option from the breadcrumbs to go back to the “User Management” page. Click on “Users”.
This page should list all the user accounts that exist in the embedded user store. By default the system has only one user account (admin) and so only that item will be listed. Click on “Add New User” to initiate the user creation wizard.
Specify “alice” as the username and “alice123” as the password and click “Next”.
Check the “creator” role from the list of available roles. The “everyone” role will be selected by default and you are not allowed by the system to uncheck that. Click on “Finish” to complete the wizard. Both “admin” and “alice” should now be listed on the “Users” page. Launch the user creation wizard once more to create another user named “bob”. Specify “bob123” as the password and make sure to add him to the “publisher” role. When finished, sign out from the management console.
So far we have created a couple of new roles and added some users to those roles. It's time to see how the API Manager utilizes the Carbon permission system. Point your web browser to https://localhost:9443/publisher to get to the API Publisher portal. Sign in using the username “alice” and password “alice123”. Since you are logging in with a user who has the “Manage > API > Create” permission, API creation options will be displayed to you.
Click on the “New API” button and create a new API (see my previous post on creating APIs). When you're finished click on the newly created API on the API Publisher home page.
You will be shown options to edit the API and add documentation, but you will not see any options related to publishing the API. To be able to publish an API, we must login as a user who has the “Manage > API > Publish” permission. So sign out from the portal and login again as the user “bob”.
First thing to note is you don't get the “Create API” option on the main menu. So go ahead and just select the API previously created by the user “alice” from the home page.
While on this page, note that there are no options available for “bob” to edit the API. However you will see a “Life Cycle” tab which wasn't visible earlier when you were logged in as “alice”. Select this tab, and you should see the options to publish the API. Select the entry “PUBLISHED” from the “State” drop down and click “Update” to publish the API. The “Life Cycle History” section at the bottom of the page will get updated saying that “bob” has modified the API status.
We are done with the API Publisher portal for the moment. Lets head out to API Store. Sign out from the API Publisher and point your browser to http://localhost:9763/store. First of all try signing in as “alice” or “bob”. You will end up with an error message similar to the following.
Only those users with the “Subscribe” permission are allowed to login to the API Store. So we need to create a new user account with the “Manage > API > Subscribe” permission. We can use the self sign up feature of API Store to do that. Click on the “Sign-up” option at the top of the API Store portal.
Create an account with the username “chris” and password “chris123”. When completed you should see a dialog box similar to the following.
Now go ahead and login as “chris”. This time the login attempt will be successful. The self sign up component, not only creates the user account, but also adds him to the “subscriber” role that we saw earlier in the management console. Since this role already has the “Manage > API > Subscribe” permission, self signed up users can always login to the API Store without any issues. Also try signing into the API Publisher portal as the user “chris”. You will get an error message similar to the following.
A word about the default “subscriber” role. This is not a role managed by the system, but rather something created by the self sign up component of the API Manager. In other words, this is the role to which all self signed up users will be assigned. You can change the name of this role by modifying the “SubscriberRoleName” parameter in the repository/conf/api-manager.xml file. If you are using an external user store, you can specify an existing role for this purpose too. If you don't want the API Manager to attempt to create this role in the system, set the “CreateSubscriberRole” parameter in api-manager.xml to “false”. If you're going to use an existing role as the subscriber role, make sure that role has the “Configure > Login” and “Manage > API > Subscribe” permissions so that the self signed up users can login to API Store and subscribe to APIs.
In order to see the effect of granting multiple API management permissions to the same role, you can use the default “admin” account. This user is in a role named “admin” which has all the permissions in the Carbon permission tree. Therefore this user can login to both API Store and API Publisher portals. On the API Publisher, he can see all the options related API creation, editing as well as publishing.
I believe you found our work on API Manager permission model interesting. Feel free to try different combinations of permissions and different types of user stores. Send us your feedback to dev@wso2.org or architecture@wso2.org.












































